실전 머신러닝에서 도메인 지식의 중요성
데이터 과학의 다양한 지식(일반적인 머신러닝 이론, 컴퓨터비전, 자연어처리 등등)을 공부한 후에 실전으로 들어가서 현업의 문제를 풀어보려고 하면 만나게 되는 하나의 장벽이 있다. 바로 해당 분야의 사전 지식, 즉 도메인 지식(Domain knowledge)이다.
 Challenges in Visual Recognition(from Stanford CS231n)
Challenges in Visual Recognition(from Stanford CS231n)
예를 들면 컴퓨터 비전의 경우 이미지가 어떤 형식으로 저장되는지(RGB, CMYK), 또는 어떤 식으로 이미지를 전처리해야 작업할 때 수월한지(Resize, Crop, Normalization), 어떤 이미지가 인식하기 어려운지 등을 알고 있어야 좀 더 효율적으로 실제 문제를 풀 수 있다. 이 밖에도 한글 자연어처리라면 형태소, 의료라면 해당 질환의 발병 기전 등의 사전 지식을 가지고 있어야 문제를 해결하는 데 도움이 된다.
금융에 머신러닝을 적용할 때에도 마찬가지로 금융 데이터에 대한 도메인 지식이 중요하다. 도메인 지식을 모를 경우 접근 방식 자체에서 헤매거나 효율적인 접근 방식을 떠올릴 수 없게 된다. 사실, 금융에 머신러닝을 적용하는 경우 도메인 지식이 없으면 문제를 푸는 것이 불가능하다. 다른 머신러닝 문제를 푸는 것과는 조금 다른 방식으로 내가 만든 모델을 평가해야 하기 때문이다.
금융 머신러닝에서 도메인 지식이 없다면 어떻게 될까
일반적으로 머신러닝을 배우고 나서 금융 데이터에 머신러닝 모델을 적용하여 문제를 해결하려고 하는 사람들은 보통 다음과 같은 실수를 하게 된다.
Case 1. 주가 데이터는 시계열 데이터니까 일단 RNN/LSTM을 적용해서 예측해보자!
가장 흔하게 볼 수 있는 유형이자, 딥러닝으로 주가 예측하기(Stock price prediction using Deep Learning)라는 내용으로 검색을 하면 수없이 많이 나오는 튜토리얼들에서 공통적으로 관찰할 수 있는 실수다. 심지어 국내에 있는 시스템 트레이딩 강의나 서적 중 일부에서도 이런 접근을 금융 머신러닝의 정석인 것처럼 가르치고 있는 것으로 보여서 다소 우려되는 점이 있다.
이런 실수를 하는 경우 보통 기존 머신러닝 모델을 학습시킬 때 하는 것처럼 데이터를 train:test = 8:2 정도로 나누고 학습을 시킨다. 이 때 나름 시계열 데이터에 따른 종속성을 제거한다고 랜덤으로 셔플하는 것이 아니라 앞부분 80%만 학습용으로, 뒷부분 20%를 테스트용으로 잘라서 데이터셋을 구성한다. 그리고 오늘의 종가를 기준으로 내일 또는 n일 뒤의 종가를 예측하도록 RNN 모델을 가지고 학습을 시킨다. 물론 학습에 쓰이는 평가지표는 일반적으로 RNN을 학습시킬 때 쓰는 MSE(Mean Squared Error)이다. 그렇게 학습을 시키면 아래 그림과 같이 너무나 아름다운 그래프가 나오게 된다.
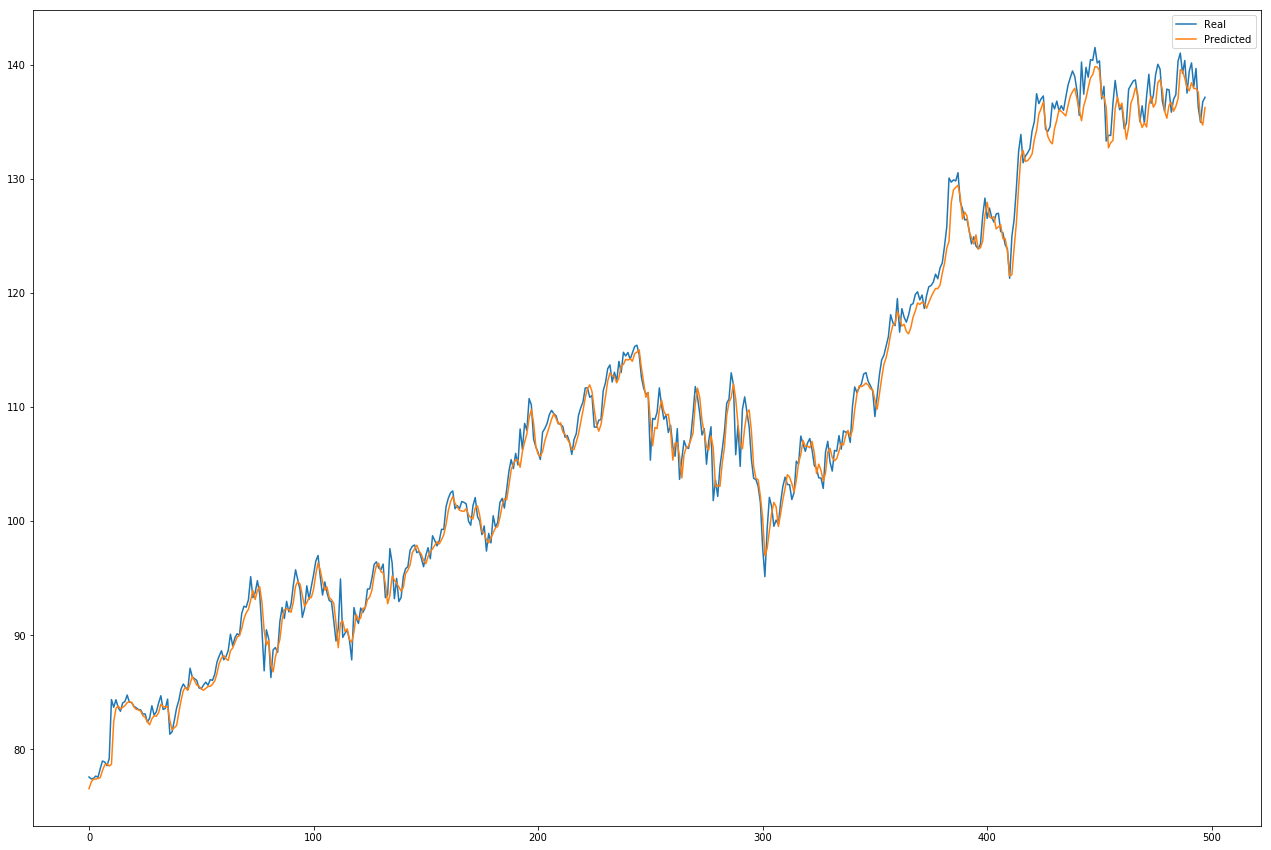
(해당 이미지는 이 튜토리얼에서 볼 수 있다)
너무 아름다운 결과는 뭔가 쎄한 법. 이렇게 간단한 방법으로 주가를 예측할 수 있다면 머신러닝 하는 사람들은 모두 부자가 되었을 것이다. 그렇다면 모두가 해피엔딩일텐데.. 하지만 그렇다. 뭔가 문제가 있다.
그래프를 잘 살펴보면, 학습된 모델이 예측하는 값들의 그래프가 원래 주가 그래프를 오른쪽으로 약간 끌어다 놓은 형태인 것을 발견할 수 있다. 결국 이 모델은 특정 주가를 입력값으로 받으면 해당 입력값과 비슷한 값을 n일 후의 주가로 예측해버린다. 학습한 모델의 입장에서는 MSE라는 evaluation metric을 잘 충족하는 예측값이겠지만, 실제 주식 투자의 입장에서는 의미가 없는 예측이다. 변동성이 엄청난 장이 아닌 한, 며칠 후의 주가는 사실 원래 주가에서 크게 바뀌지 않기 때문이다. 다른 시계열 문제와 달리 주가는 투자자들의 Anchoring Bias에 영향을 받는 특성이 있다.
모델이 학습한 방식에는 문제가 없다. 이 경우 문제는 이런 방식으로 학습 과정을 구성한 사람에게 있다. (‘컴퓨터는 잘못이 없다. 잘못은 코드를 작성한 프로그래머에게 있다.’ 라는 말과 비슷해 보이는 건 기분 탓일까..) MSE를 evaluation metric으로 과거 주가 데이터를 학습시키려 하면 이와 같은 shifted prediction 문제를 만나게 될 것이다.
Case 2. 일단 확보할 수 있는 데이터를 다 때려박고 AutoML 돌려서 예측해보자! & 이 때 주가에 영향을 주는 요인은 xx더라!
이런 실수를 하는 경우는 크게 두 가지 유형일 것 같은데, 하나는 AutoML에 대한 지나친 믿음이 있고, 다른 하나는 꼭 AutoML이 아니더라도 머신러닝에 대한 지나친 믿음+기존의 금융 지식과 설명 가능성에 대한 등한시가 함께 합쳐지는 경우다.
최근 AutoML 솔루션이 잘 나오고 있고 다양한 분야에 적용할 수 있음이 알려지면서 금융 쪽에서 AutoML을 적용하려는 시도가 존재한다. 혹은 꼭 AutoML이 아니더라도 다양한 머신러닝 모델을 적용하고 그 중 좋은 모델을 선택하여 실제 트레이딩까지 하려고 할 수 있다. 이 때 데이터와 학습 방법의 특성을 고려하지 않고 단순히 있는 방법을 가져다 쓸 때 발생하는 문제가 바로 Selection Bias under Multiple Testing이다.
Selection Bias under Multiple Testing에 대해서는 나중에 추가로 글을 작성할 것이기에 간단하게만 설명하겠다. 예를 들면 한 투자회사가 Sharpe Ratio(위험 대비 수익률 지표)가 2 이상인 펀드매니저를 채용한다고 하자. 이를 위해 다양한 지원자들과 면접을 진행할텐데, 이 경우 새로운 지원자들을 볼 때마다 Sharpe Ratio의 기준을 2보다 더 높이지 않으면 문제가 발생한다. 랜덤하게 투자하는 원숭이를 계속 면접 보더라도, 수없이 많은 원숭이들을 보게 되면 2 이상의 SR을 갖는 원숭이를 찾을 수 있게 된다. (더 자세한 내용은 이 논문을 참고)
AutoML의 기본적인 원리는 모델이나 사용하는 feature를 바꿔가면서 여러 번 테스트하여 좋은 성능을 가지는 아키텍처와 feature들의 목록을 찾아내는 것이기 때문에, Selection Bias under Multiple Testing를 피해갈 수 없다. 아니면 나중에 추가로 작성할 Deflated Sharpe Ratio 등의 방법을 사용하는 방식으로 접근해야 한다. 다양한 머신러닝 모델을 활용하거나 Hyperparameter tuning을 하는 등 Multiple testing을 하는 등의 경우도 마찬가지다. 특히 K-fold Cross Validation을 사용하는 경우 테스트 데이터가 모델 개발 과정에서 여러 번 반복되어 사용되면 Selection Bias under Multiple Testing가 발생한다.
그리고 이러한 이유와 더불어, feature selection과 모델 해석의 입장에서도 완전히 data-driven하는 기존 머신러닝 접근법과는 다르게, 설명 가능한 XAI 기술을 적용하고 어느 정도 기존에 밝혀진 경제학 이론으로 너무 이상한 결과들을 filtering하는 것이 필요하다. 최근 국내 모 은행에서 AI 전담 조직을 만들고 기사를 냈는데, 대표가 해당 기사에서 S&P500 지수를 예측하는 데 남아공 데이터가 유의미한 변수로 나왔다며 기존의 사람이라면 이를 배제시켰겠지만 우리는 딥러닝을 믿기 때문에 오류가 아니라면 괜찮다는 취지로 얘기한 것을 본 적이 있다. 이는 금융 도메인뿐만 아니라 머신러닝/딥러닝에 대해 합리적인 의심 없이 무조건 믿는 사람들이 자주 하는 실수이기도 한데, 현재 머신러닝/딥러닝 모델들은 인과관계가 아닌 상관관계만 파악할 수 있다. 따라서 이러한 상관관계를 인과관계로 간주하거나 착각하여 발생하는 실수를 피할 수 있어야 한다.
현대 포트폴리오 이론으로 노벨경제학상을 받은, 계량금융학의 선구자 중 하나인 Harry Markowitz가 최근 교신저자로 발표한 A Backtesting Protocol in the Era of Machine Learning 논문에 좋은 예시가 하나 있다. 다음 그래프를 하나 보자.
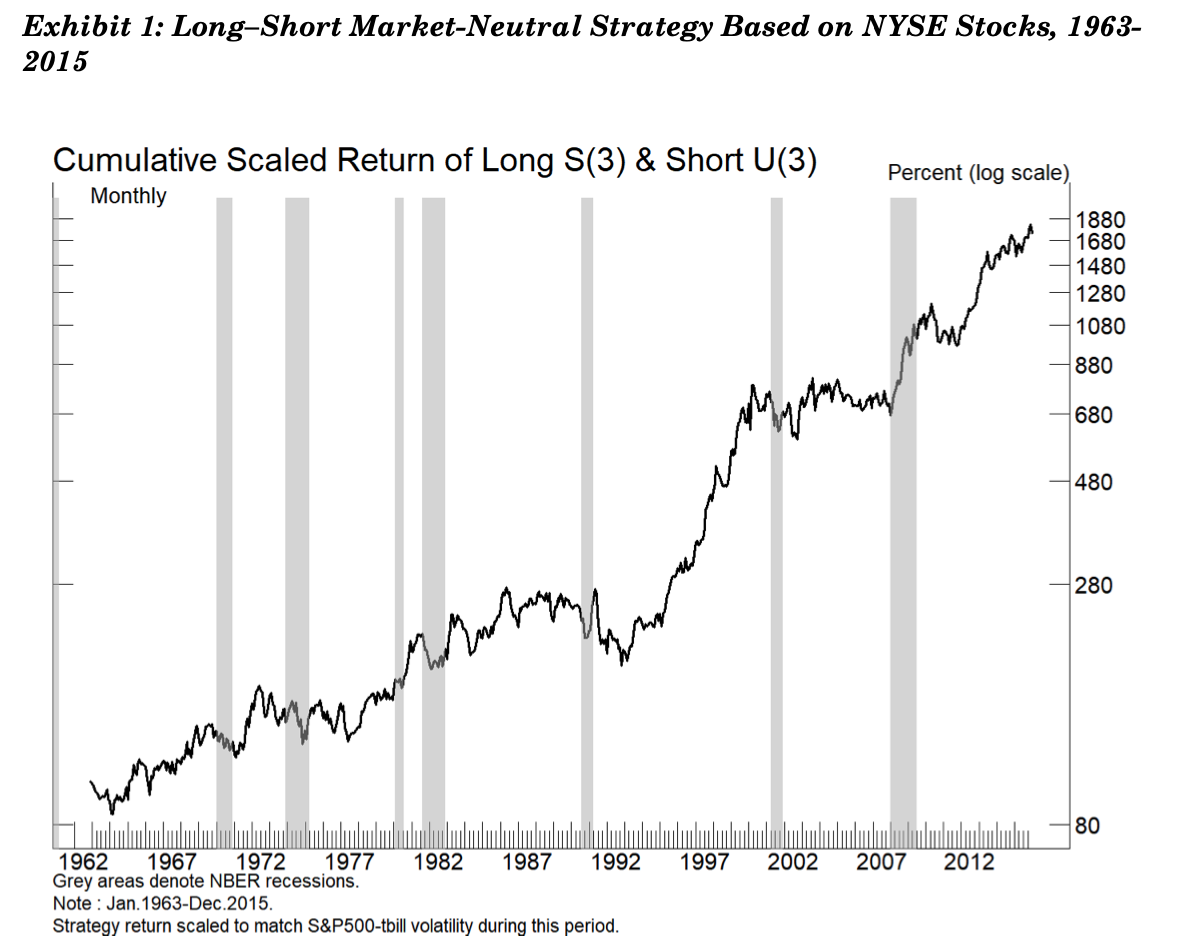
위 그림은 long-short equity 전략의 투자 성과 그래프인데, 가짜 결과가 아니고 실제 백테스팅 결과다. 이 전략은 1963년부터 1988년까지의 NYSE 데이터를 기반으로 학습해 만들어진 시장중립(Market-neutral, 시장의 등락과 무관하게 항상 이익을 창출하는) 전략이다. 심지어 out-of-sample validation 데이터셋은 학습 데이터셋보다 더 긴 1989년부터 2015년까지의 자료이고, 이 때 수익률이 학습 데이터셋보다 더 높다. 전략의 Sharpe ratio는 매우 인상적인데 50년간의 백테스팅에서 연간 6%의 이익을 창출하고 있고, 이는 통계적으로도 유의미하다. 이 전략은 심지어 (1) 일관적으로 좋은 성과를 내고 있고 (2) 최근까지도 성과가 나빠진 적이 없으며 (3) 경제 위기가 온 때에도 꽤 성과가 잘 나왔고 (4) 잘 알려진 다른 factor인 value, size, momentum과 통계적인 상관관계가 없으며(이것은 해당 factor를 사용하는 다른 전략들과 함께 포트폴리오로 구성될 때 매우 유리해진다는 것을 뜻함) (5) 회전율(turnover)이 연 10% 미만으로 매우 낮아 거래비용을 무시할 수 있을 정도이다. 이런 5가지나 되는 좋은 전략의 요소까지 갖추고 있다.
그러나 다시 한 번, 너무 아름다운 결과는 뭔가 쎄한 법. 이 전략은 단순히 주식 티커명을 가지고 만든 전략이다. 예를 들면 A(1)-B(1) 전략은 티커명의 첫 글자가 A인 모든 주식에 Long 전략을, 첫 글자가 B인 모든 주식에 Short 전략을 적용한다. 위 그래프에 나온 전략은 S(3)-U(3)로 티커명의 3번째 글자가 S인 주식들을 Long하고 3번째 글자가 U인 주식들을 Short한 전략이다. 알파벳에는 26개나 되는 글자가 있으니 3글자의 티커명에다 Long-Short 페어링 전략으로 만들 수 있는 조합은 수천개가 된다. 이 경우 모든 조합을 찾아보면 그 중 좋아보이는 전략을 찾을 가능성이 상당히 높다. 저자들이 만든 프로젝트 페이지에 가보면 좀 더 많은 그럴듯한 백테스트 결과 예시를 찾을 수 있다.
결국 정리해보면 주식 이름으로 랜덤하게 뽑는, 말도 안 되는 전략도 수없이 백테스트를 돌려보면 그 중 하나는 좋은 결과가 나올 수 있다. 또 다시 얘기하면 경제지표를 기반으로 한 백테스팅도 말도 안 되는 overfitting 결과이지만 통계적 유의성은 매우 높게 나올 수 있다. 해당 논문의 저자는 ‘우리는 현실 세계의 자산을 기반으로 투자하는 것이다. 모델에 너무 집중해서 모델이 현실 세계의 approximation이라는 것을 잊으면 안 된다’고 말한다. 그리고 이러한 이상한 결과를 걸러낼 수 있는 방법 중 하나로 기존의 금융 지식과 경제 이론을 함께 사용할 것을 제안한다. 최소한 설명가능한 결과를 사용하라는 것이다.
머신러닝을 의심 없이 맹신하면 안 된다. 특히 금융에서는. 왜 되는지, 왜 안 되는지 알아야 한다. 머신러닝/딥러닝이 블랙박스다, 라고 주장하며 결과를 그대로 믿어버리는 사람들이 있지만 그렇게 해도 되는 분야가 있고 아닌 분야가 있다. 금융은 돈이 걸려 있는 곳이고 대부분의 펀드는 고객의 돈을 위탁받아 투자하는 방식이기 때문에 그런 식으로 접근하는 것은 매우 위험하다.
Case 3. 주가 그래프 이미지를 CNN으로 학습시켜서 예측해보자!
이 경우 보통 이미지 인식에 있어서 CNN이 성능이 가장 좋으니까 이걸 주가 예측에도 적용해보고 싶다는 생각이 들면서 시도해보게 된다. 시도 자체가 틀린 것은 아닌데, 데이터와 모델에 대한 이해가 부족한 상태로 접근을 하면 왜 잘 되는지, 왜 잘 안 되는지를 이해할 수 없게 된다는 게 문제다. 또 효율적으로 학습되는 머신러닝 모델 아키텍처에 대해서도 충분히 고려하지 않을 경우 이상한 곳에 시간 낭비, 자원 낭비를 하게 된다. 금융 데이터에 대한 이해와 머신러닝 모델에 대한 충분한 이해 없이 단순히 CNN을 이미지 인식에서 성능이 좋다는 이유로 사용하면 다음과 같은 내용을 고려하지 못한 상태로 작업을 진행하게 된다.
CNN이 컴퓨터 비전에서 좋은 성능을 보였던 이유는 본질적으로 다음과 같이 LeNet 논문에서 밝힌 이유에 기인한다.
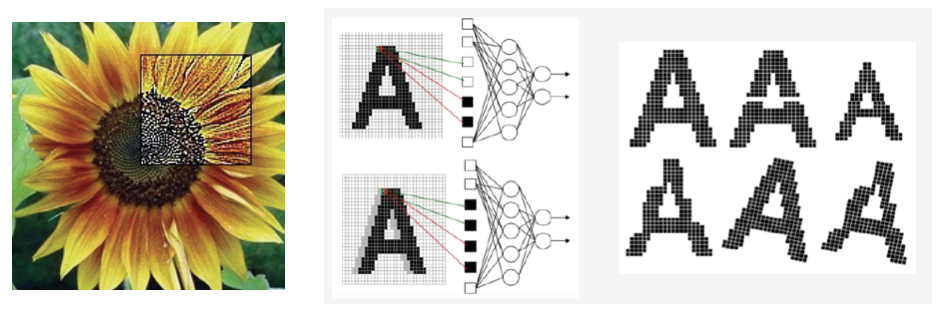 이미지라는 것은 보통 하나의 픽셀이 주변의 다른 픽셀과 연관성을 가지는 특성이 있다. 그런데 기존의 이미지 인식 알고리즘이나 단순 MLP 같은 머신러닝 모델은 단순 벡터 형식 데이터만을 다룰 뿐 주변 픽셀과의 공간적 연관성을 반영하지 못한다. 또, 픽셀의 위치가 조금만 바뀌거나 크기, 회전, 변형 등이 생기는 경우 완전히 새로운 학습이 필요했다.(다시 말해 topology 변화에 대응이 어려웠다.)
이미지라는 것은 보통 하나의 픽셀이 주변의 다른 픽셀과 연관성을 가지는 특성이 있다. 그런데 기존의 이미지 인식 알고리즘이나 단순 MLP 같은 머신러닝 모델은 단순 벡터 형식 데이터만을 다룰 뿐 주변 픽셀과의 공간적 연관성을 반영하지 못한다. 또, 픽셀의 위치가 조금만 바뀌거나 크기, 회전, 변형 등이 생기는 경우 완전히 새로운 학습이 필요했다.(다시 말해 topology 변화에 대응이 어려웠다.)
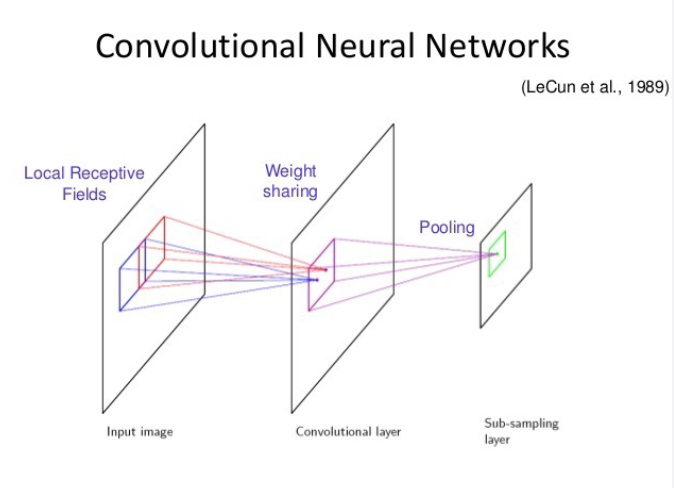 그러나 CNN은 Local Receptive Field라는 개념을 도입해 이전 layer의 모든 unit에서 데이터를 입력받는 것이 아닌, 이웃하는 일부 unit에서만 데이터를 입력받을 수 있게 했다. 그리고 Convolutional Filter는 다음 layer로 보내는 결과값을 만들 때 단지 입력 unit의 위치만 달라질 뿐, 같은 가중치를 공유하는 weight sharing 특성을 가진다. 또 Pooling layer은 위치 정보, 코너나 선 특징, 이미지의 노이즈나 왜곡 등을 고려하기 위해 해상도를 줄여서 그 대략적인 특징을 뽑아낼 수 있도록 sub-sampling 효과를 가진다.
그러나 CNN은 Local Receptive Field라는 개념을 도입해 이전 layer의 모든 unit에서 데이터를 입력받는 것이 아닌, 이웃하는 일부 unit에서만 데이터를 입력받을 수 있게 했다. 그리고 Convolutional Filter는 다음 layer로 보내는 결과값을 만들 때 단지 입력 unit의 위치만 달라질 뿐, 같은 가중치를 공유하는 weight sharing 특성을 가진다. 또 Pooling layer은 위치 정보, 코너나 선 특징, 이미지의 노이즈나 왜곡 등을 고려하기 위해 해상도를 줄여서 그 대략적인 특징을 뽑아낼 수 있도록 sub-sampling 효과를 가진다.
결론적으로 CNN은 이미지의 공간적 특성을 잘 뽑아낼 수 있는 아키텍처를 통해 이미지 인식이라는 문제에서 뛰어난 성능을 달성할 수 있었다.
그렇다면 이를 주가 예측에 사용한다면 고려해야 할 것은 무엇일까? 당연히 내가 CNN 모델에 넣고자 하는 주가 데이터의 형태가 의미있는 공간적 특성을 가지고 있는지에 대한 고민이다. 이런 고민 없이 그냥 주가 그래프를 캡쳐하여 RGB 데이터로 2D CNN 모델에 넣었다면 음.. 내가 치열하게 고민하지 않으면 내 계좌에서 돈이 사라질 확률이 높아진다는 사실에 유의하자.
고민 없이 그냥 주가 그래프를 그대로 2D CNN 모델에 넣는다면 오히려 다음과 같은 비효율성이 발생한다. 먼저 주가 데이터는 본질적으로 1D 시계열 형태이다. 이를 2D로 늘린다면 그만큼 1D에 비해 feature space가 어마어마하게 증가하게 되는 것이다. 만약 해당 데이터에 유의미한 공간적 특성이 없을 경우, 같은 feature space 대비 유의미한 정보량의 비율이 급격하게 줄어드는 것이다. 이는 전처리를 통해 머신러닝 모델이 정보를 추출하기 쉬운 형태로 바꾸는 일반적인 방식에 오히려 역행(!)하는 접근법일 수 있다. 게다가 RGB까지 적용하게 된다면 단순한 1D 데이터를 거의 3D에 가깝게 뻥튀기하는 것이라 보면 된다. 볼린저 밴드니 RSI니 다양한 지표를 추가로 넣어서 할 수 있다고 얘기하는 사람도 있겠으나, 아시다시피 주가 데이터는 대부분이 하얀색 빈 화면이기 때문에.. 이미지 형태로 넣는 것이 정말 큰 의미가 있는 전처리 방식일까라는 의문이 든다. 추가적인 지표 또한 1D로 생성이 가능하기 때문에 그대로 1D feature로만 추가하면 된다. 물론 전처리는 정답이 없는 문제이고, 이미지로 구성하더라도 정말 효과적인 방법이 있다면 당연히 시도해볼 만하다. 하지만 개인적으로는 주가 데이터의 특성과 모델 아키텍처를 고려해봤을 때 차라리 1D CNN이 좀 더 적절한 모델이 아닐까 싶다.
나도 이런 실수를 해본 적이 있다
처음 금융 분야에 머신러닝을 적용할 때, 위와 같은 실수를 했다고 해서 자책할 필요는 전혀 없을 것 같다. 금융 데이터는 굉장히 특수한 분야이고 아직도 밝혀내야 할 것들이 많은 분야이기 때문이다. 게다가 그 난이도에 비해 어떻게 접근하는 것이 좋은지에 대한 명확한 가이드라인 혹은 좋은 튜토리얼을 찾기 어려운 상황인 것 같다. 그래서 어쩌면 다른 분야에 머신러닝을 적용하던 사람들이 처음 금융 분야로 프로젝트를 시작할 때 이런 실수를 하는 것이 당연한 것일지도 모른다.
개인적으로도 처음 금융 분야에 머신러닝을 적용했을 당시 토이 프로젝트에서 비슷한 실수를 한 적이 있다. 당시 다양한 주식 및 펀더멘탈 데이터를 활용해 각 산업군의 ETF 가격을 예측하려 했는데, 금융 데이터에 대한 이해 없이 다른 머신러닝 프로젝트에서 하던 방식을 그대로 가져와 적용했었다. 당시 어느 정도 성능이 나와서 성과를 만들었다고 생각했지만 이후 좀 더 깊게 공부를 하다보니 일종의 overfitting이 존재했고, 특히 selection bias under multiple testing도 존재했음을 알 수 있었다. 만약 이 프로젝트를 그대로 활용하여 투자를 했다면? 아마 내 계좌에는 파란 불이 켜지고 내 눈에서는 피눈물이..
가장 엄격한 잣대로 정확하게 작업해야 하는 도메인을 꼽으라면 보통 의료와 금융이라고들 한다. 하나는 사람의 목숨이 달린 일이고 다른 하나는 재산이 달린 일이니 맞는 말이다. 돈이 걸린 일인 만큼 좀 더 꼼꼼하게 공부해서 제대로 프로젝트를 진행하는 것이 좋으리라 생각된다. 아예 이 내용을 몰랐다면 모를까, 알게 된 후부터는 제대로 도메인 지식 공부를 하고 난 후 프로젝트를 진행해야겠다는 생각이 들게 되더라.
금융 머신러닝에서 도메인 지식을 얼마나 알아야 할까
그렇다면 문제는, 금융 머신러닝을 하기 위해서 어느 정도의 도메인 지식이 필요할까 라는 것이다.
물론 정답은 없겠지만 개인적으로는 다음과 같은 지식이 필요할 것이라 생각한다.
- 금융 머신러닝 결과를 평가하기 위한 지표들
- 의미 있는 결과를 만들어내기 위한 백테스팅 전략 구성법
- 금융 머신러닝의 학습 및 배포 파이프라인 구성 요소
- 금융 데이터의 종류와 특성, 전처리 방법과 각 전처리 방법의 특징
- 기존 금융 이론과 경제 이론
이 중 1, 2번은 금융 머신러닝 프로젝트를 진행하기 위한 최소한의 요건이고, 3, 4번은 알고 있으면 프로젝트를 효율적으로 진행할 때 도움이 될 내용들이다. 특히 4번은 좀 더 다양한, 심화된 시도를 하고자 할 때 필요한 내용들이고 제대로 활용하고자 하면 금융 도메인 지식뿐만 아니라 머신러닝의 통계적, 수리적 기반 이론, 시계열 데이터의 특징 등 다양한 내용도 함께 알고 있어야 한다. 5번은 알고 있으면 아이디어를 생각해내는 데 도움이 될 내용이다.
해당 지식들은 나도 아직 공부를 진행하고 있는 중이라 앞으로도 공유하기 좋은 내용들은 정리하여 블로그에 포스팅할 예정이다.
그리고 누군가 ‘그럼 이 분야를 무엇으로 어떻게 공부해야 하나요’라고 묻는다면, 현재 이 분야에서 활발하게 연구를 하고 있는 Marcos López de Prado의 논문과 책을 읽어보라고 권하고 싶다. 특히 Advances in Financial Machine Learning은 매우 추천하는 책 중 하나다. 이 밖에도 최근 새로 만들어진 국제 금융 자격증인 Financial Data Professional(FDP)의 커리큘럼 내에 있는 논문들도 좋은 읽을거리라 생각된다.
아무래도 머신러닝/딥러닝 자체가 다시 주목을 받게 된지도 얼마 되지 않은데다 도메인 지식의 중요성이 높은 금융 분야에 본격적으로 적용하게 된 것은 더 최근의 일이라 체계적이고 정리된 공부 소스가 많지는 않은 상태인 것 같다. 더군다나 중요한 발견을 하면 바로 공개하여 학계의 검증을 받는 과학 분야들과 달리 이 분야는 공개하게 되면 알파(수익을 낼 수 있는 시장의 feature)가 사라지는 경우가 많다보니 알려진 전략들은 단물이 쏙 빠진 철 지난 전략들인 경우가 많다. 그래서 스스로 살 길을 찾아가야 하는 외로운 분야인 것 같기도 하고.. 그래도 어느 분야나 그렇듯이 선구자가 존재하고 그들의 생각과 지혜를 잘 정리해서 제시하고 있다. 이 때 공부하는 학생이 가져야 할 자세와 태도는 합리적인 의심과 다양한 시각으로 제대로 된 선생님을 찾고, 그 내용을 선별적으로 잘 받아들이는 것이라고 생각한다. 그리고 이 분야는 여러 학문이 복합적으로 합쳐져 만들어지는 융합 분야인 만큼 머신러닝, 금융, 통계, 수학, 컴퓨터공학 등 다양한 분야의 최신 트렌드도 지속적으로 follow-up 하는 것이 중요하다.
+) 최근 인공지능 퀀트 코리아라는 페이스북 그룹이 만들어져 공부하면서 배우는 좋은 정보를 공유할 수 있을 것 같다. 해당 그룹을 통해 앞으로 작성하는 글을 공유해볼 예정이다.