Model Interpretability와 관련한 Monotonicity에 대해 공부하다가, 괜찮은 글들을 번역해 정리해보았다.
Introduction
보통 실제 머신러닝이나 데이터사이언스 문제에서는 머신러닝 모델을 활용해 2개 이상의 변수들이 가지고 있는 수치적 관계를 찾는다. 예를 들면, 호텔 체인 회사의 경우 머신러닝을 활용해 가격 산정 전략을 최적화하고 특정 요일에 객실이 예약될 가능성을 추정할 수 있다. 이 추정 과정에는 한 가지 가정이 존재하는데, 다른 것들이 모두 동일하면 가격이 쌀수록 고객들이 선호할 것이고 따라서 저렴한 가격에 더 많은 수요가 존재한다는 가정이다. 그러나 이 경우 실제로 머신러닝 모델을 만들 때 문제가 발생한다. 예를 들면 모델이 고객이 화요일에 $100이 아니라 $110을 지불하는 것을 선호한다고 예측하는 경우다. 이러한 문제가 발생하는 이유는 가격과 예약 가능성 사이에 monotonic relationship이 있을 것으로 기대가 되는 것에 반해 머신러닝 모델은 데이터의 노이즈나 예외 사례 때문에 이를 완전히 잡아내지 못한다는 데 있다.
현업에 있는 사람들이 꽤 자주 이런 constraints을 무시하고는 하는데, 특히 Random forest나 Gradient boosted tree, Neural Network 계열 알고리즘이 쓰일 때 그렇다. 그리고 monotonicity constraints이 학계에서 꽤 오랫동안 하나의 주제로 있었음에도 불구하고(tree based model에 대한 monotonocity constraints의 서베이 논문은 여기를 참고하자) 이 기능을 지원하는 라이브러리가 부족하여 현업자들에게 어려움을 주고 있었다.
다행히도 최근 몇 년간 머신러닝 라이브러리들에 많은 발전이 있어서 LightGBM이나 XGBoost와 같은 가장 유명한 gradient boosted tree 라이브러리에 monotonicty constraints을 설정할 수 있는 기능이 포함되었다. 또 constrained and interpretable lattice based models를 만드는 새로운 방법(논문은 여기 참고)을 구현한 Tensorflow Lattice 라이브러리에도 포함되어 있다.
Monotonicity constrains in LightGBM and XGBoost
tree based methods (decision tree, random forests, gradient boosted trees)에 한해서는 모델을 학습시키는 과정에서 monotonicity constraints를 깨지게 하는 monotonic featrues split을 하지 않음으로써 monotonicity를 유지할 수 있다.
다음 예시에서 monotonic한 관계를 갖는(그렇지만 노이즈도 포함되어 있는) X와 Y 두 변수의 관계를 파악할 때 monotone constraints을 적용한 LightGBM 모델과 그냥 기본 모델을 학습시켜보고 비교해보자.
1 | |
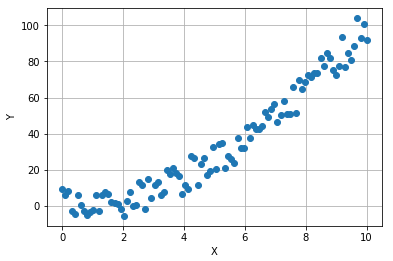
이 데이터에 gradient boosted model을 학습시켜보자. min_child_samples는 5로 설정한다.
1 | |
이 모델은 약간 오버피팅 될 것이다(min_child_samples이 작기 때문). X에 따른 모델의 예측치를 빨간 선으로 그려보면 해당 선은 우리가 원하는 monotonic한 특성을 가지고 있지 않다.

우리는 X와 Y가 monotonic한 특성을 가지고 있다고 알고 있기 때문에, 모델을 생성할 때 constraint을 적용할 수 있다.
1 | |
파라미터 monotone_constraints = “1” 설정은 결과값이 첫번째 변수에 대해 monotonically increasing해야 한다는 것을 의미한다. (이 예시에서는 독립변수가 1개만 있음) 이 모델을 학습하고 나면 결과가 monotone으로 나오는 것을 확인할 수 있다.

그리고 모델의 성능을 살펴보면, monotonicity constraint가 모델이 좀 더 자연스러운 학습을 하게 만들뿐만 아니라 일반화도 잘 하게 만들어준다는 것을 확인할 수 있다. 새로운 test 데이터에 대해 Mean squared error를 계산해보면 monotone 모델에서 error가 더 작다.
1 | |
1 | |
Other methods for enforcing monotonicity
monotonicity constraint을 적용할 수 있는 모델은 tree based method만 있는 건 아니다. Tensorflow Lattice는 최근에 개발된 lattice based model 구현체들의 모음이다. 임의의 input-output에 대해 그 관계를 근사하는 interpolated look-up table을 만들 수도 있고, monotonic 옵션을 넣을 수도 있다. tutorial도 있으니 Github repository 가서 보면 된다.
만약 데이터가 이미 주어졌을 경우, splinefun 패키지 등을 활용해 monotonic spline을 데이터에 맞춰 학습시킬 수도 있다.
참고 링크
https://blog.datadive.net/monotonicity-constraints-in-machine-learning/