Contribute to Keras 프로젝트에서 진행한 Keras 튜토리얼 번역문. 이 문서는 인간의 사전 지식 없이도 게임을 마스터할 수 있는 일반화된 강화학습 알고리즘인 AlphaZero에 대해 다룬다. AlphaGo -> AlphaGo Zero, AlphaZero로 이어지는 해당 알고리즘의 간략한 역사와 함께, AlphaZero가 어떤 방식으로 학습하는지 쉽게 설명한다. 여기에 더불어 이해를 돕기 위해 원문 저자의 AlphaGo Zero에 대한 cheat sheet 또한 번역하여 첨부하였다. (예정) 또 Connect4 게임에 AlphaZero 알고리즘을 적용한 코드에 대해 간략하게 설명한다.
원문: (Medium) How to build your own AlphaZero AI using Python and Keras, David Foster
- AlphaGo
- 강화학습
- 에이전트(Agent)
- 상태(State)
- 가치(Value)
- 정책(Policy)
- 행동(Action)
- 몬테 카를로 트리 서치(Monte Carlo Tree Search)
- Residual Convolutional Network
부제: 컴퓨터가 자가 경기(self-play)와 딥러닝을 통해 Connect4 게임의 전략을 배울 수 있도록 가르쳐보자
이 글에서는 3가지에 대해 다룹니다:
- AlphaZero가 왜 인공지능으로 향하는 큰 발걸음인지에 대한 2가지 이유
- AlphaZero 방법론을 따라한 모델을 만들어 Connect4라는 게임을 플레이하는 방법
- 그 코드를 다른 게임에도 적용하는 방법
AlphaGo -> AlphaGo Zero -> AlphaZero
2016년 3월, 2억 명이 지켜보는 가운데 DeepMind의 AlphaGo가 세계대회 18관왕의 바둑 선수 이세돌을 4-1로 이겼습니다. 기계가 인간을 능가하는 바둑 전략을 학습한 것이죠. 이는 기존에 불가능하다고 생각되었던 것으로, 달성하려면 최소한 10년은 더 걸릴 것이라고 여기던 일입니다.

이것은 그 자체로 엄청난 업적이었습니다. 그러나 2017년 10월 18일, DeepMind는 하나의 더 큰 도약을 이뤄냅니다.
‘인간의 지식 없이 바둑을 마스터하기(Mastering the Game of Go without Human Knowledge)’ 라는 논문은 기존 알고리즘의 새로운 변형이자 AlphaGo를 100대 0으로 이긴 AlphaGo Zero를 소개합니다. 놀랍게도 이것은 오직 자가대국을 통해 학습한 결과이며, 백지에서 시작해 점진적으로 자기 자신을 이기는 새로운 전략을 찾아가는 과정을 통해 이루어졌습니다. 인간을 능가하는 인공지능을 만드는 데 있어 더 이상 인간 전문가들의 대국 데이터베이스가 필요하지 않게 된 것입니다.
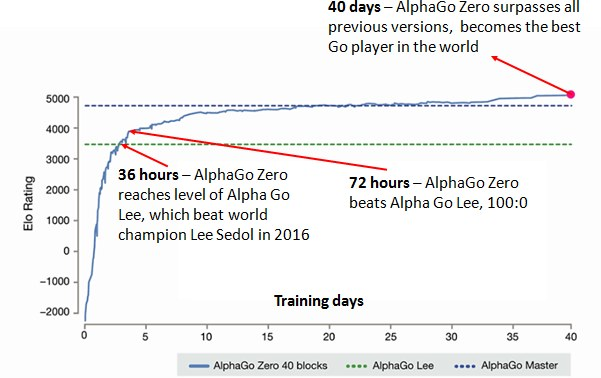
그로부터 겨우 48일이 지난 2017년 12월 5일, DeepMind는 또다른 논문 ’일반화된 강화학습 알고리즘을 활용한 자가 경기를 통해 체스와 쇼기 게임 마스터하기’(Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm)‘를 공개했습니다. 이 논문은 Alphago Zero를 체스와 Shogi 게임 각 분야에 적용하여 해당 분야 세계 최고의 프로그램인 StockFish와 Elmo를 이길 수 있음을 보였습니다. 이 모든 학습 과정에 있어, 컴퓨터 프로그램이 처음 게임을 마주한 순간부터 해당 분야의 세계 최고가 되기까지는 24시간이 채 걸리지 않았습니다.
인간 전문가의 전략에 대한 어떠한 사전 지식 없이도, 빠르게 어떤 분야를 잘 해낼 수 있는 일반화된 알고리즘 AlphaZero는 이렇게 탄생했습니다.
AlphaZero의 놀라운 2가지 점은 다음과 같습니다:
1. AlphaZero는 인간의 지식을 입력값으로 필요로 하지 않는다
이 점이 얼마나 중요한지는 두말할 필요도 없습니다. 이것은 어떤 게임이든 간에 완전 정보적(플레이어들이 항상 게임의 상태를 파악할 수 있는)이기만 하면 AlphaGo Zero의 방법론을 적용할 수 있다는 것입니다. 왜냐하면 게임의 규칙 외에는 어떤 선행 지식도 필요하지 않기 때문이죠.
이것은 DeepMind가 AlphaGo Zero 논문을 낸 지 단 48일 만에 체스와 shogi 게임에 대한 논문을 새로 낼 수 있었던 배경이기도 합니다. 말 그대로, 이를 위해 필요로 했던 것은 게임의 동작 원리를 설명하는 입력 파일을 바꾸는 것과 신경망 및 몬테 카를로 트리 서치(Monte Carlo Tree Search)와 관련된 하이퍼파라미터(Hyperparameter)를 수정하는 것이 전부였습니다.
2. 알고리즘이 놀라우리만큼 명쾌하다
만일 AlphaZero가 고작 세계에서 몇 명 안 되는 사람들만 이해할 수 있는 매우 복잡한 알고리즘을 썼더라도, 그건 여전히 엄청난 기술이었을 것입니다. 그러나 AlphaZero가 대단한 점은 논문 내에 있는 수많은 아이디어들이 그 이전 버전의 논문들보다 사실상 훨씬 덜 복잡하다는 것입니다. 그리고 그 본질에는 학습에 대한 이 아름다운 주문(mantra)이 자리잡고 있습니다.
머릿속에서 미래의 가능한 시나리오를 플레이하고, 좋은 경로(path)에 대해 우선순위를 두면서, 동시에 다른 플레이어가 너의 행동(action)에 어떻게 반응(react)할지를 생각하고, 아직 모르는 수들을 탐험하라.
생소한 상태(state)를 마주하면, 네 생각에 얼마나 그 수가 좋은지를 평가해라. 그리고 그렇게 평가한 점수를 이 수까지 이르게 된 머릿속 경로 내의 이전 수들에 전달한다.
미래의 가능성에 대한 생각이 끝나고 나면, 가장 많이 탐험한 그 행동(action)을 취하라.
게임이 끝나면, 다시 돌아가 가치를 잘못 판단한 미래의 수들에 대해 평가하고 그에 따라 가치를 업데이트해라.
실제로 게임을 배우는 것과 비슷하게 들리지 않나요? 만약 잘못된 수를 두었다면, 이는 그 결과의 미래 가치를 잘못 계산했거나, 상대가 어떤 수를 둘 가능성을 잘못 판단해 그 가능성에 대해 생각해보지 않았기 때문일 것입니다. 이것들이 바로 AlphaZero가 학습하는 게임의 두 가지 측면입니다.
어떻게 AlphaZero를 만들 수 있을까
먼저, AlphaGo Zero가 어떻게 학습하는지 대략적으로 이해하기 위해 AlphaGo Zero cheat sheet를 살펴봅시다. 코드의 각 파트를 살펴보면서 이것을 참조하면 좋으리라 생각됩니다. 추가적으로 AlphaZero가 어떻게 작동하는지 좀 더 자세히 설명하는 좋은 글 도 있습니다.
코드
여기서 설명하려는 코드는 이 Github repository에 있으니 클론합시다.
학습 과정(learning process)을 시작하려면, run.ipynb 라는 Jypyter notebook 파일의 상단에 있는 2개의 셀을 실행하면 됩니다. 메모리를 채울 정도로 충분한 경우의 수가 만들어지면 신경망이 학습을 시작합니다. 추가적인 자가경기(self-play)와 학습을 통해, 신경망은 점진적으로 해당 게임의 가치와 어떤 위치에서의 다음 수를 잘 예측하게 됩니다. 그 결과 보다 나은 의사 결정과 전반적으로 보다 영리한 경기를 할 수 있게 됩니다.
이제 코드를 좀 더 자세히 들여다보고, 인공지능이 시간이 지남에 따라 강해지는 것을 보여주는 결과들을 살펴볼까요.
주의: 이것은 논문을 통해 얻은 정보를 바탕으로 AlphaZero가 어떻게 작동하는지를 저 스스로 이해한 것입니다. 만약 아래 내용 중 뭔가 잘못되었다면, 죄송하다는 말씀 드리며 그 부분 고치기 위해 노력하겠습니다.
Connect4
우리의 알고리즘이 학습하고자 하는 게임은 Connect4(혹은 Four In A Row라는 이름)입니다. 바둑과 같이 복잡한 것은 아니지만.. 그럼에도 여전히 총 4,531,985,219,092개의 경우의 수가 존재합니다.

Connect4 하는 법. 이해를 돕기 위해 역자가 추가로 삽입하였습니다.

이 게임의 룰은 간단합니다. 플레이어들은 번갈아가며 자기의 색깔을 가진 돌을 각 열의 꼭대기에 넣습니다. 먼저 가로, 세로, 또는 대각선으로 4개의 돌을 놓는다면 승리합니다. 만약 모든 공간이 다 찼는데도 연속으로 4개의 돌이 놓이지 않았다면 그 게임은 무승부입니다.
여기 코드를 구성하는 핵심 파일들의 요약본이 있습니다:
game.py
이 파일은 Connect4의 게임 규칙을 담고 있습니다.
각 정사각형(Square)들에는 다음과 같이 0부터 41까지의 번호가 할당되어 있습니다:
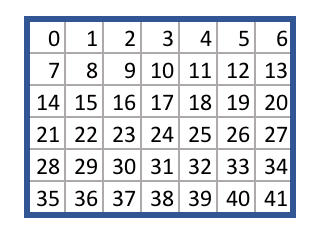
game.py 파일은 주어진 행동(action)에 따라 어떠한 게임 상태(state)에서 다른 상태로 바뀌는 로직(logic)을 담고 있습니다. 예를 들면, 비어 있는 게임판과 행동 38이 주어지면, takeAction 메소드(method)가 먼저 시작하는 플레이어의 돌이 가운데 열의 바닥에 놓여진 새 게임 상태(state)를 반환합니다.
game.py 파일을 같은 API 방식을 따르는 게임 파일로 대체할 수도 있는데, 그러면 알고리즘이 그 파일에 주어진 규칙에 따라 자가 경기(self play)를 하며 전략(strategy)를 학습합니다.
run.ipynb
이 파일은 학습 과정을 시작하는 코드를 포함하고 있습니다. 이 코드는 게임 규칙을 로드한 다음 알고리즘의 메인 루프문(main loop)을 반복합니다. 이 루프문은 다음과 같이 세 단계로 구성됩니다:
- 자가경기(Self-play)
- 신경망을 다시 학습하기(Retraining the Neural Network)
- 신경망을 평가하기(Evaluating the Neural Network)
이 루프문에 관련된 두 에이전트(agent)가 있는데, 각각 best_player와 current_player입니다.
best_player는 가장 좋은 성능을 내는 신경망을 가지고 자가 학습 메모리(self play memories)를 생성하는 데 사용됩니다. 그러면 current_player는 이 메모리를 기반으로 자신의 신경망을 다시 학습시켜 best_player와 대전합니다. 만약 여기서 승리한다면 best_player가 가지고 있던 신경망은 current_player가 가진 신경망으로 교체되며, 루프문은 다시 시작됩니다.
agent.py
이 파일은 Agent 클래스(게임 내의 플레이어)를 포함합니다. 플레이어들을 각각의 신경망과 몬테 카를로 서치 트리(Monte Carlo Search Tree)와 함께 초기화됩니다.
simulate 메소드는 몬테 카를로 트리 서치 프로세스를 실행합니다. 구체적으로 말하면, 에이전트(agent)가 트리의 리프 노드(leaf node)로 이동하고, 해당 노드를 에이전트가 가진 신경망으로 평가한 뒤, 해당 값을 반영하여 트리 상단에 있는 노드들의 값을 다시 채우죠.
act 메소드는 시뮬레이션을 여러 번 반복하여 현재 위치에서 어떤 수를 두는 것이 가장 유리한지를 파악합니다. 그 후 선택한 행동(action)을 게임에 반환합니다.
replay 메소드는 이전 게임들에서의 메모리를 활용하여 신경망을 다시 학습합니다.
model.py
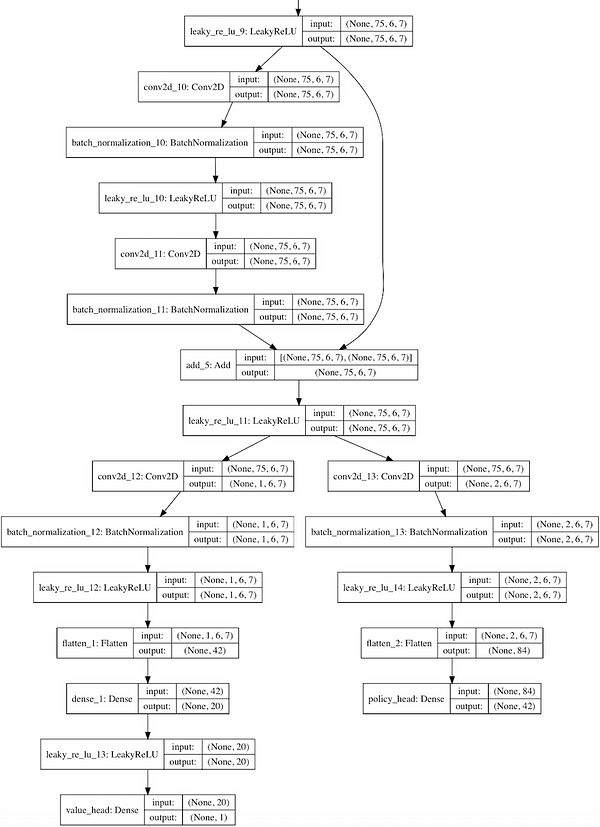
이 파일에는 신경망의 인스턴스(instance)를 만드는 방법을 정의하는 Residual_CNN 클래스가 포함되어 있습니다.
이것은 AlphaGo Zero 논문에 있는 신경망 구조의 간략화된 버전입니다. 다시 말해 convolutional layer와 그 뒤에 붙는 많은 residual layer들이 있고, 이후 가치 머리(value head)와 정책 머리(policy head)로 나누어집니다.
convolutional filter들의 깊이와 개수는 config 파일에 명시되어 있습니다.
신경망을 만들기 위해 케라스 라이브러리를 사용하고, 텐서플로우를 백엔드(backend)로 사용합니다.
신경망 내에 있는 각 convolutional filter들과 densely connected layer들을 시각화하기 위해서는, run.ipynb 노트북 파일 내에 있는 다음과 같은 코드를 실행하면 됩니다.
1 | |
MCTS.py
이 파일은 몬테 카를로 서치 트리(Monte Carlo Search Tree)를 구성하는 노드(Node)와 엣지(Edge) 그리고 MCTS 클래스들을 포함합니다.
MCTS 클래스는 이전에 언급한 moveToLeaf와 backFill 메소드를 가지고 있으며, 엣지(Edge) 인스턴스(instance)들은 각 잠재적 수들에 대한 통계값들을 가지고 있습니다.
config.py
이 파일은 알고리즘에 영향을 주는 핵심 파라미터(key parameter)들을 설정한다.
1 | |
이 변수들을 조정하면 실행 시간이나 신경망의 정확도, 그리고 알고리즘의 전반적인 성공 여부에 영향을 주게 됩니다. 위의 파라미터(parameter)들은 고성능의 Connect4 플레이어를 만들겠지만, 시간이 많이 걸릴 것입니다. 알고리즘의 속도를 높이기 위해서는 다음과 같은 파라미터(parameter)들을 대신 쓰면 됩니다.
1 | |
funcs.py
이 파일은 두 에이전트(agent) 간 경기를 할 수 있게 하는 playMatches와 playMatchesBetweenVersions 함수를 가지고 있습니다.
직접 만든 것으로 경기를 하고 싶다면, 다음과 같은 코드를 실행하면 됩니다.(run.ipynb 노트북 파일 내에도 있습니다)
1 | |
initialise.py
알고리즘을 실행시키면, 모든 모델과 메모리 파일은 루트 디렉토리에 있는 run 폴더에 저장됩니다.
나중에 어떤 체크포인트(checkpoint)에서 다시 알고리즘을 실행시키고 싶다면, run 폴더에서 run_archive 폴더로 옮긴 후 폴더 이름에 실행 번호를 붙입니다. 그런 다음 initialise.py 파일 내부에 run_archive 폴더 내 관련된 파일 위치에 해당하는 실행 번호와 모델 버전 번호, 그리고 메모리 버전 번호를 입력하면 됩니다. 그 후 평소와 같이 알고리즘을 실행하면 해당 체크포인트에서부터 시작하게 됩니다.
memory.py
Memory 클래스의 인스턴스는 지난 게임들에 대한 메모리를 보관하며, 이는 알고리즘이 current_player의 신경망을 다시 학습하는 데 쓰입니다.
loss.py
이 파일은 사용자가 정의한(custom) loss function을 포함합니다. 이것은 잘못된(illegal) 수에서 비롯된 예측값이 cross entropy loss function에 넘겨지는 것을 막아줍니다.
settings.py
run과 run_archive 폴더의 위치를 포함합니다.
loggers.py
로그(Log) 파일들은 run 폴더 내의 log 폴더에 저장됩니다.
로깅(logging) 기능을 켜려면, 이 파일 내에 있는 logger_disabled 변수를 False로 설정해주면 됩니다.
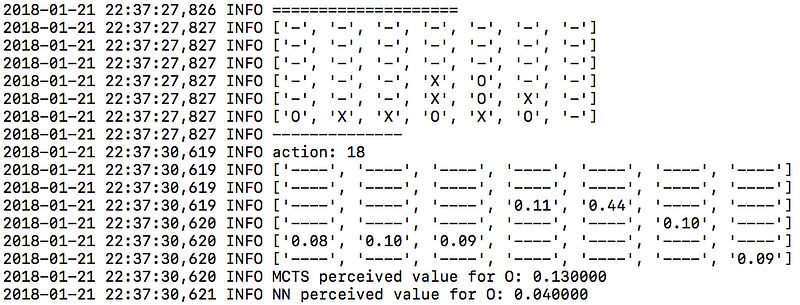
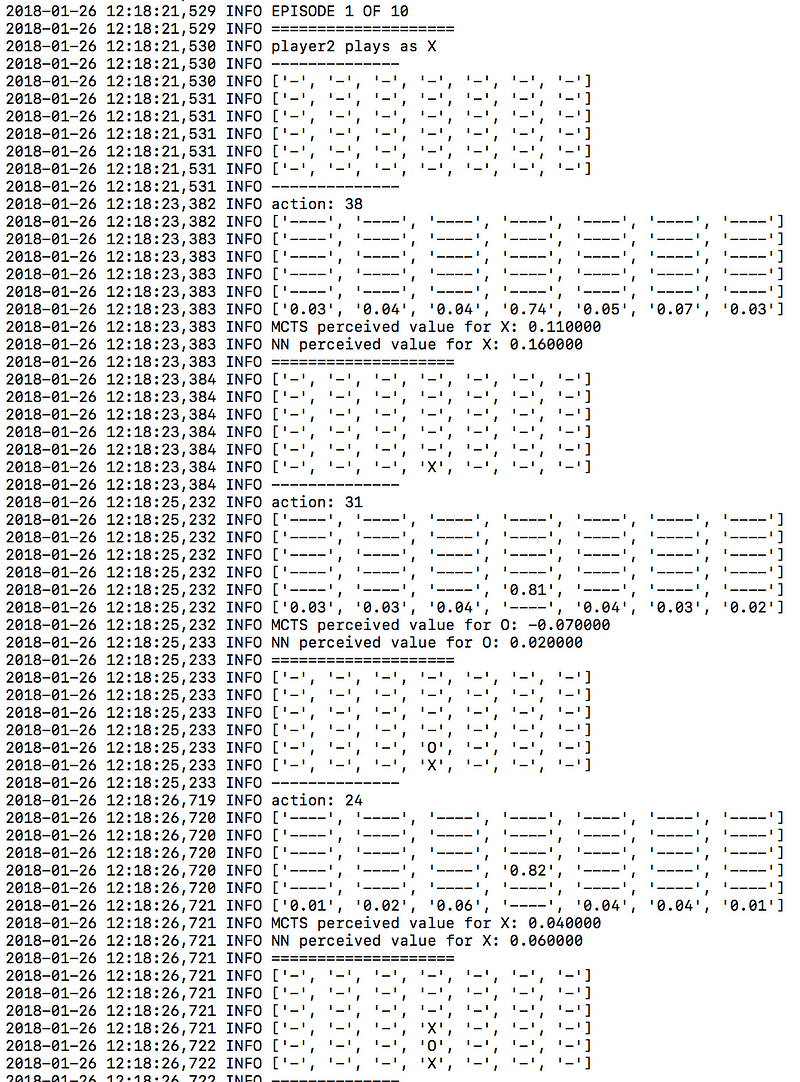
로그 파일을 보면 알고리즘이 어떻게 작동하는지 이해하는 데 도움을 줄 것이고, 그것의 ‘마음(mind)’을 살펴볼 수 있습니다. 예를 들면, 여기 logger.mcts 파일에서 가져온 샘플을 볼까요.

logger.tourney 파일에서도 마찬가지로, 평가 단계(evaluation phase)에서 각 수에 대한 확률값들을 확인할 수 있습니다.
결과
며칠 간의 학습을 통해 다음과 같이 mini-batch 반복(iteration) 숫자에 따른 loss 차트를 구할 수 있었습니다.
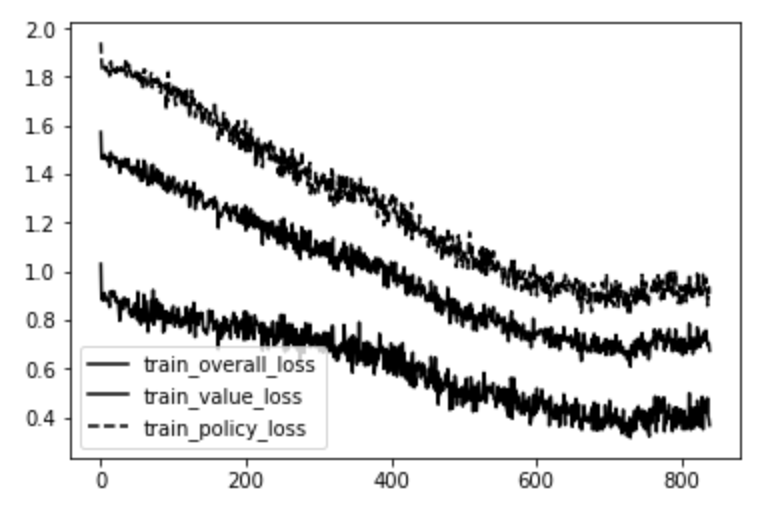
가장 위에 있는 선은 정책 머리(policy head)에서 나온 에러(MCTS에서 나온 각 수에 대한 확률과 신경망에서 나온 결과 간의 cross entropy)입니다. 가장 아래 있는 선은 가치 머리(value head)에서 나온 에러(실제 게임의 가치와 신경망이 평가한 가치 사이의 mean squared error)입니다. 가운데 있는 선은 그 둘의 평균값입니다.
분명히, 신경망은 각 게임 상태(state)의 가치와 그 다음 움직임(move)을 점점 잘 예측하게 됩니다. 이렇게 점점 강해지는 것을 보여주기 위해, 반복(iteration)을 1번만 한 신경망에서부터 49번을 한 신경망까지 총 17개의 플레이어 간 리그를 시켰습니다. 각 플레이어는 두 번씩 맞붙었는데, 이는 두 플레이어 모두 첫 수를 두는 기회를 주기 위해서였습니다.
여기 그 최종 순위가 있습니다:
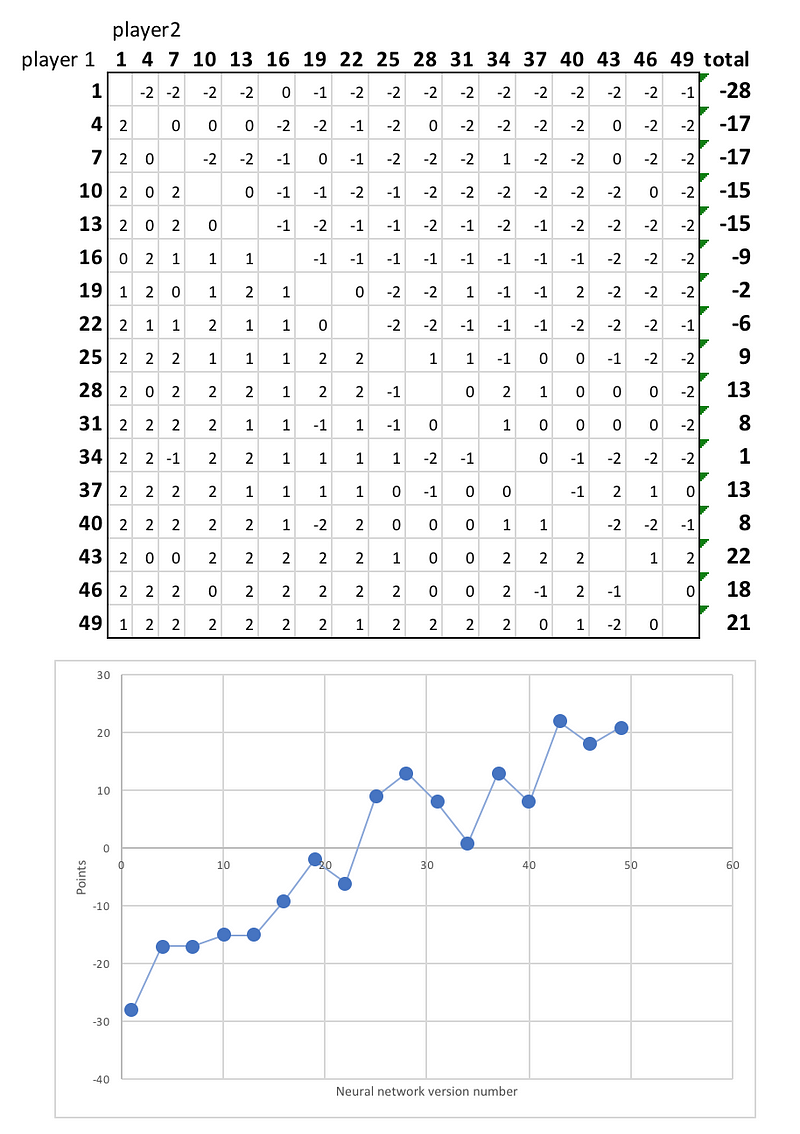
확실히, 신경망의 후기 버전이 대부분의 게임에서 초기 버전에게 이기며 더 뛰어난 모습을 보여주었습니다. 또한 아직 학습이 정점에 달한 것 같지는 않아 보여, 추가적인 학습 시간이 있다면 플레이어가 더 많은 복잡한 전략을 학습해 보다 강해질 수 있을 것입니다.
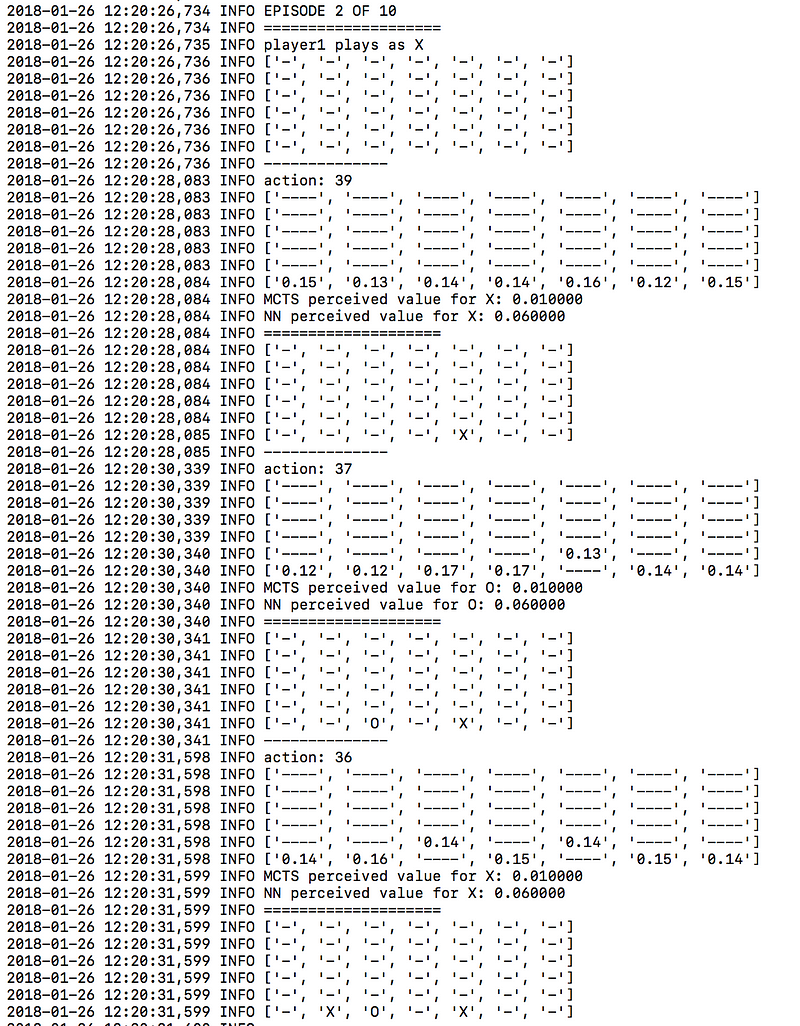
예를 들면, 시간이 지남에 따라 신경망이 좋아하게 되는 확실한 전략은 가운데 열을 빠르게 접수하는 것입니다. 알고리즘의 1번째 버전과 30번째 버전의 차이를 살펴봅시다.
신경망 첫번째 버전
신경망 30번째 버전
많은 선들이 가운데 열을 필요로 하기 때문에, 이를 선점하여 상대가 이점을 가져가지 못하게 하는 전략은 좋은 전략이라고 할 수 있습니다. 신경망은 인간의 어떠한 도움도 없이 이 전략을 학습했습니다.
다른 게임을 학습하기
games 폴더 안에는 ‘Metasquares’라는 게임을 위한 game.py 파일이 있습니다. 이것은 X와 O 마커를 격자판 내에 놓으면서 다른 크기의 정사각형을 만드는 게임입니다. 큰 정사각형일수록 작은 정사각형보다 더 큰 점수를 얻을 수 있고, 격자판이 모두 찼을 때 더 많은 점수를 가진 플레이어가 승리합니다.
Metasquares 게임 화면. 이해를 돕기 위해 역자가 추가로 삽입하였습니다.
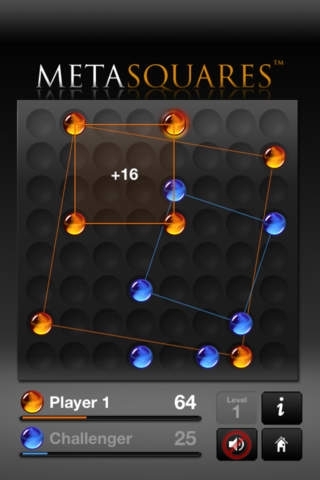
Connect4의 game.py 파일을 Metasquares 게임의 game.py로 바꾸면, 같은 알고리즘이 대신 Metasquares 게임을 하는 방법을 학습하게 됩니다.
맺으며
이 글이 도움이 되었기를 바랍니다. 만약 코드나 글에 오타나 질문이 있다면, 아래 댓글로 남겨주면 최대한 빨리 답해드리겠습니다.

만약 우리 회사 Applied Data Science가 어떻게 기업을 위한 혁신적인 데이터 사이언스 솔루션을 만드는지 궁금하다면, 우리의 웹사이트나 LinkedIn을 통해 자유롭게 연락하기를 부탁드립니다.
… 그리고 이 글을 좋아한다면, 따뜻한 박수(이 글이 업로드된 Medium 플랫폼은 박수 아이콘을 눌러 좋아요를 표시할 수 있습니다: 역자)를 보내주길 부탁드립니다 :)
Applied Data Science는 기업을 위한 end-to-end 데이터 사이언스 솔루션을 구현하여 중요한 가치를 전달하는, 런던 기반 자문 회사입니다. 만약 당신이 가진 데이터로 뭔가를 더 해보고 싶으시다면 연락 주세요.
의역과 역자의 해석에 따른 추가적인 설명이 포함되어 원작자의 의도가 다르게 전해질 여지가 있으니 유의하시기 바랍니다. 만약 오역이나 오타를 발견하신다면 karl6885@gmail.com으로 메일 주시면 감사하겠습니다.
이 글은 2018 컨트리뷰톤에서
Contributue to Keras프로젝트로 진행했습니다.Translator : karl6885(김영규)
Translator Email : karl6885@gmail.com